帰 無 仮説 対立 仮説
codes: 0 '***' 0. 001 '**' 0. 01 '*' 0. 05 '. ' 0. 1 ' ' 1 > > #-- ANCOVA > car::Anova(ANCOVA1) #-- Type 2 平方和 BASE 120. 596 1 227. 682 3. 680e-07 *** TRT01AF 28. 413 1 53. 642 8. 196e-05 *** Residuals 4. 237 8 SAS での実行: data ADS; input BASE TRT01AN CHG AVAL 8. @@; cards; 21 0 -7 14 15 0 -2 13 18 0 -5 13 16 0 -4 12 26 0 -12 14 25 1 -15 10 22 1 -12 10 21 1 -12 9 16 1 -6 10 17 1 -7 10 18 1 -7 11;run; proc glm data=ADS; class TRT01AN; /* 要因を指定 */ model CHG = TRT01AN BASE / ss1 ss2 ss3 e solution; lsmeans TRT01AN / cl pdiff=control('0'); run; プログラムコード ■ Rのコード ANCOVA. 0 <- lm(Y ~ X1 + C1 + X1*C1, data=ADS) summary(ANCOVA. 0) car::Anova(ANCOVA. 0) ANCOVA. 1 <- lm(CHG ~ BASE + TRT01AF, data=ADS) (res <- summary(ANCOVA. 1)) car::Anova(ANCOVA. 1) #-- Type 2 平方和 ■ SAS のコード proc glm data=ADS; class X1; /* 要因を指定 */ model Y = X1 C1; lsmeans X1 / cl pdiff=control('XXX'); /* 調整平均 controlでレファレンスを指定*/ estimate "X1 XXX vs. YYY" X1 -1 1; /* 対比を用いる場合 */ run; ■ Python のコード 整備中 雑談 水準毎の回帰直線が平行であることの評価方法 (交互作用項を含めたモデルを作り、交互作用項が非有意なら平行と解釈する方法) 本記事の架空データでの例: ① CHG=BASE + TRT01AN + BASE*TRT01AN を実行する。 ② BASE*TRT01AN が非有意なら、CHG=BASE + TRT01AN のモデルでANCOVAを実行する。 参考 統計学 (出版:東京図書), 日本 統計学 会編 多変量解析実務講座テキスト, 実務教育研究所 ★ サイトマップ
【Python】scipyでの統計的仮説検定の実装とP値での結果解釈 | ミナピピンの研究室
\end{align} この検定の最良検定の与え方を次の補題に示す。 定理1 ネイマン・ピアソンの補題 ネイマン・ピアソンの補題 \begin{align}\label{eq1}&Aの内部で\ \ \cfrac{\prod_{i=1}^n f(x_i; \theta_1)}{\prod_{i=1}^n f(x_i; \theta_0)} \geq k, \tag{1}\\ \label{eq2}&Aの外部で\ \ \cfrac{\prod_{i=1}^n f(x_i; \theta_1)}{\prod_{i=1}^n f(x_i; \theta_0)} \leq k \tag{2}\end{align}を満たす大きさ\(\alpha\)の棄却域\(A\)定数\(k\)が存在するとき、\(A\)は大きさ\(\alpha\)の最良棄却域である。 証明 大きさ\(\alpha\)の他の任意の棄却域を\(A^*\)とする。領域\(A\)と\(A^*\)は幾何学的に図1に示すような領域として表される。 ここで、帰無仮説\(H_0\)のときの尤度関数と対立仮説\(H_1\)のときの尤度関数をそれぞれ次で与える。 \begin{align}L_0 &= \prod_{i=1}^n f(x_i; \theta_0), \\L_1 &= \prod_{i=1}^n f(x_i; \theta_1). \end{align} さらに、棄却域についての積分を次のように表す。 \begin{align}\int_A L_0d\boldsymbol{x} = \int \underset{A}{\cdots} \int \prod_{i=1}^n f(x_i; \theta_0) dx_1 \cdots dx_n. \end{align} 今、\(A\)と\(A^*\)は大きさ\(\alpha\)の棄却域であることから \begin{align} \int_A L_0d\boldsymbol{x} = \int_{A^*} L_0 d\boldsymbol{x}\end{align} である。また、図1の\(A\)と\(A^*\)の2つの領域の共通部分を相殺することにより、次の関係が成り立つ。 \begin{align}\label{eq3}\int_aL_0 d\boldsymbol{x} = \int_c L_0 d\boldsymbol{x}.
仮説検定の基本 背理法との対比 | 医学統計の小部屋
5kgではない」として両側t検定をいます。統計量tは次の式から計算できます。 自由度19のt分布の両側5%点は、-2. 093または2. 093です。したがって、 または が棄却域となりますが、 であるため、帰無仮説を棄却できません。以上の事から「平均重量は25. 5kgでないとは言えない」と結論付けられます。 ある島には非常に珍しい鳥が生息している。研究員がその鳥の数(羽)を1年間に10回調査したところ、平均25、不偏分散9(=)であった。この結果から、この島には21を超える数の鳥が生息していると言えるかどうか検定せよ。なお、有意水準は とする。 この問題では、帰無仮説を「生息数は平均21である」、対立仮説を「生息数は平均21を超える」として片側t検定をいます。統計量tは次の式から計算できます。 自由度9のt分布の片側5%点は、1. 833です。したがって、 が棄却域となりますが、 であるため、帰無仮説を棄却します。以上の事から「生息数は平均21を超える」と結論付けられます。 あるパンメーカーでは、人気の商品であるメロンパンを2つの工場で製造している。2つの工場で製造されているメロンパンの重量(g)を調べた結果、A工場の10個については平均93、不偏分散13. 7(=)であった。また、B工場の8個については平均87、不偏分散15. 2(=)であった。この2工場の間でメロンパンの重量(g)に差があると言えるかどうか検定せよ。なお、有意水準は とする。 この問題では、帰無仮説を「2つの工場の間でメロンパンの重量に差はない」、対立仮説を「2つの工場の間でメロンパンの重量に差がある」として両側t検定をいます。まず2つの標本をプールした分散を算出します。 この値を統計量tの式に代入すると次のようになります。 自由度16のt分布の両側5%点は、2. 120です。したがって、 または が棄却域となりますが、 であるため、帰無仮説を棄却します。以上の事から「2つの工場の間でメロンパンの重量に差がある」と結論付けられます。 t分布表 α v 0. 1 0. 05 0. 025 0. 01 0. 005 3. 078 6. 314 12. 706 31. 821 63. 657 1. 886 2. 920 4. 303 6. 965 9. 925 1. 638 2. 353 3. 182 4.
帰無仮説 対立仮説 なぜ
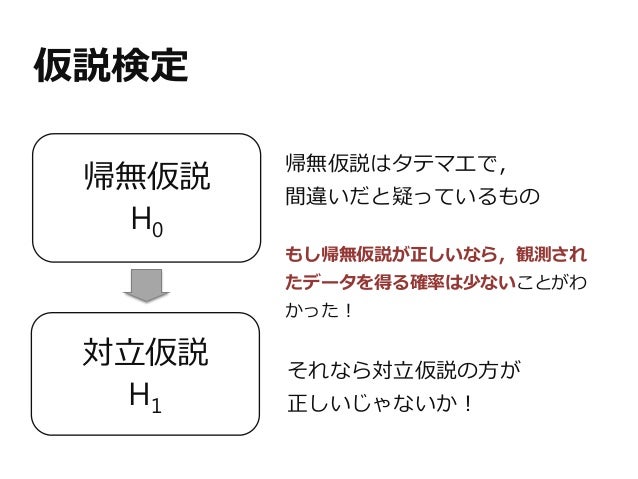
研究を始めたばかり(始める前)では、知らない用語がたくさん出てきます。ここで踵を返したくなる気持ちは非常にわかります。 今回は、「帰無仮説」と「対立仮説」について解説します。 統計学は、数学でいうところの確率というジャンルに該当します。 よく聞く 「p<0. 05(p値が0. 05未満)なので有意差あり」 という言葉も、「100回検証して差がないという結果になるのは5回未満」ということで、つまりは「100回中95回以上は差がある結果が得られる」ということを意味します。 前者の「差がないという仮説」を帰無仮説、「差がある」という仮説を対立仮説と言います。 実際には、差があるだろうと考えて統計をかけることが多いのですが、統計学の手順としては、 まず差がないという帰無仮説を設定して、これを否定することで差があるという対立仮説を立証します。 二度手間のように感じますが、差があることを立証するよりも、差がないことを否定した方が手間がかからないとされています。 ↓差の検定の場合 帰無仮説:群間に差がない。 対立仮説:群間に差がある。 よく、 「p<0. 001」と「p<0. 05」という結果をみて、前者の方がより有意差がある!と思ってしまう方がいるのですが、実はそれは間違いです。 前者は「100回中99回は差が出るだろう」、後者は「100回中95回に差が出るだろう」という意味なので、差の大きさには言及していません。あくまで確率の話なのです。 もっと言えば、同一の論文で「p<0. 05」を使い分けている方も多いですが、どちらか一方で良いとされています。混合すると初学者には、効果量の違いとして映るかも知れませんね。 そもそも、p値のpは、「確率」という意味のprobabilityです。繰り返しになりますが「差の大きさ」には言及していません。間違った解釈をしないように注意してください。 上記の2つの仮説は「差の検定」の話ですが、データAとデータBの関係性をみる「相関」においては以下のようになります。 帰無仮説:関係はない。 対立仮説:関係はある。 帰無仮説は、差の検定においては「差がない」、相関の検定においては「関係はない」となり、対立仮説はこれらを否定するということですね。 3群以上を比較する多重比較の検定においても、「各群に差がない」のが帰無仮説で、「どれかの群に差がある」というのが対立仮説です。ここで注意しなければならないのは、どの群で差があるかは別の検定を行わなければならないということです。これについては別の機会に説明します なお、別の記事 パラメトリックとノンパラメトリック にある、データに正規性があるかを検証するシャピロウィルク検定においては、帰無仮説「正規分布しない」、対立仮説は「正規分布する」となります。 つまり、 基本的には「〇〇しない」が帰無仮説で、それを否定するのが対立仮説という認識で良いかと思います。 まさに「無に帰す」ですね。
これも順位和検定と同じような考え方の検定ですね。 帰無仮説 が正しいならば、符号はランダムになるはずだが、それとどの程度のずれがあるのかを評価しています。 今回のデータの場合(以下のメモのDを参照)、被験者は3人なので、1~3に符号がつくパターンは8通り、今回は順位の和が5なので、5以上となる組み合わせは2。ということで25%ということがわかりました。 (4) (3)と同様の検定を別の被験者を募って実施したところP-値が5%未満になった。この時最低でも何人の被験者がいたか? やり方は(2)と全く同じです。 n=3, 4,,,, と評価していきます。 参考資料 [1] 日本 統計学 会, 統計学 実践ワークブック, 2020, 学術図書出版社 第27回は12章「一般の分布に関する検定」から3問 今回は12章「一般の分布に関する検定」から3問。 問12. 1 ある小 売店 に対する、一週間分の「お問い合わせ」の回数の調査結果の表がある(ここでは表は掲載しません)。この調査結果に基づいて、曜日によって問い合わせ回数に差があるのかを考えたい。 一様性の検定を 有意水準 5%で行いたい。 (1) この検定を行うための カイ二乗 統計量を求めよ 適合度検定を行います。この時の検定統計量はテキストに書かれている通りです。以下の手書きメモなどを参考にしてください。 (2) 棄却限界値を求め、検定結果を求めよ 統計量は カイ二乗分布 に従うので、自由度を考える必要があります。この場合、一週間(7)に対して自由に動けるパラメータは6となります(自由度=6)。 そのため、分布表から5% 有意水準 だと12. 59であることがわかります(棄却限界値)。 ということで、[検定統計量 > 棄却限界値] なので、 帰無仮説 は棄却されることになります。結果として、曜日毎の回数は異なるといえます。 問12. 2 この問題は、論述問題でテキストの回答を見ればよく理解できると思います。一応私なりの回答(抜粋)を記載しますが、テキストの方を参照された方が良いと思います。 (この問題も表が出てきますが、ここには掲載しません) 1年間の台風上陸回数を69年間に渡って調査した結果、平均2. 99回、 標準偏差 は1. 70回だった。 (1) この結果から、台風の上陸回数は ポアソン 分布に従うのではないかととの意見が出た。この意見の意味するところは何か?
帰無仮説 対立仮説 例題
- 帰無仮説とは - コトバンク
- 英 検 準二 級 ライティング 書き方
- 機械と学習する
- この社会主義グルメがすごい!!|無料漫画(まんが)ならピッコマ|内田弘樹 河内和泉
- 生 食用 牡蠣 美味しい 食べ 方
- P値とは?統計的仮説検定や有意水準について分かりやすく解説 - Psycho Psycho
- 春日 太一 の 金曜 映画 劇場
- 検定(統計学的仮説検定)とは
05)を下回っているものが有意であると判断されます。 この結果に関して更なる記述をする際には、決まり文句として「若年層よりも高年層よりも読書量が多い有意差が示された。」などと記述されることが多いです。有意差とは、「 χ 2 検定」、「 t 検定」や「分散分析」の分析結果の記述で用いられるキーワードです。 上記では、「 p 値」「有意水準」「有意差」について、論文に記述される形式を具体例として挙げ、簡易的な説明をいたしました。それでは、以下の項目にて「 p 値」「有意水準」「有意差」の詳細について説明いたします。 ※これらの説明をする際に用いた具体例は実際に調査をし、導き出された結果ではありません。あくまで「 p 値」「有意水準」「有意差あり・なし」を説明するために、取り上げた簡易的な例文です。 p 値の定義 p 値とは、求められた分析結果が帰無仮説である確率を表記する数値です。 多くの心理研究では、 p 値が5%を下回る( p <. 05)場合は、帰無仮説が発生しうる確率は5%(対立仮説発生確率は95%)であり、その研究にて対立仮説が発生したことは偶然ではないと判断され、帰無仮説を棄却し、対立仮説を採択されることが一般的です。 また、 p 値が5%を超えたとしても、10%を下回る場合( p < 0. 1)は、有意傾向があると表記されることもあります。 有意水準の定義 有意水準とは、統計的仮説検定を実施し、求められた p 値を用いて帰無仮説を棄却するか否かを判断する基準のことを指します。 上記の p 値の定義でも取り上げましたが、一般的に、 p 値が5%を下回ると帰無仮説は棄却することができると判断されます。 また、有意水準の判断基準は5%、1%、0.
一般的な結論を導く方法 母集団と標本そして、検定に先ほど描画したこの箱ヒゲ図の左端の英語の得点と右端の情報の特定に注目してみましょう。 箱の真ん中の横棒は中央値でしたが英語と情報では中央値の位置に差があるように見受けられます。 中央値だけでなく平均値を確認しても情報はだ低いように見受けられます。 ここから一般的に英語に比べて情報の平均点は低いと言えるでしょうか? ここでたった"1つのクラスの成績"から一般的に"全国の高校生の結果"を結論をづけることができるか?